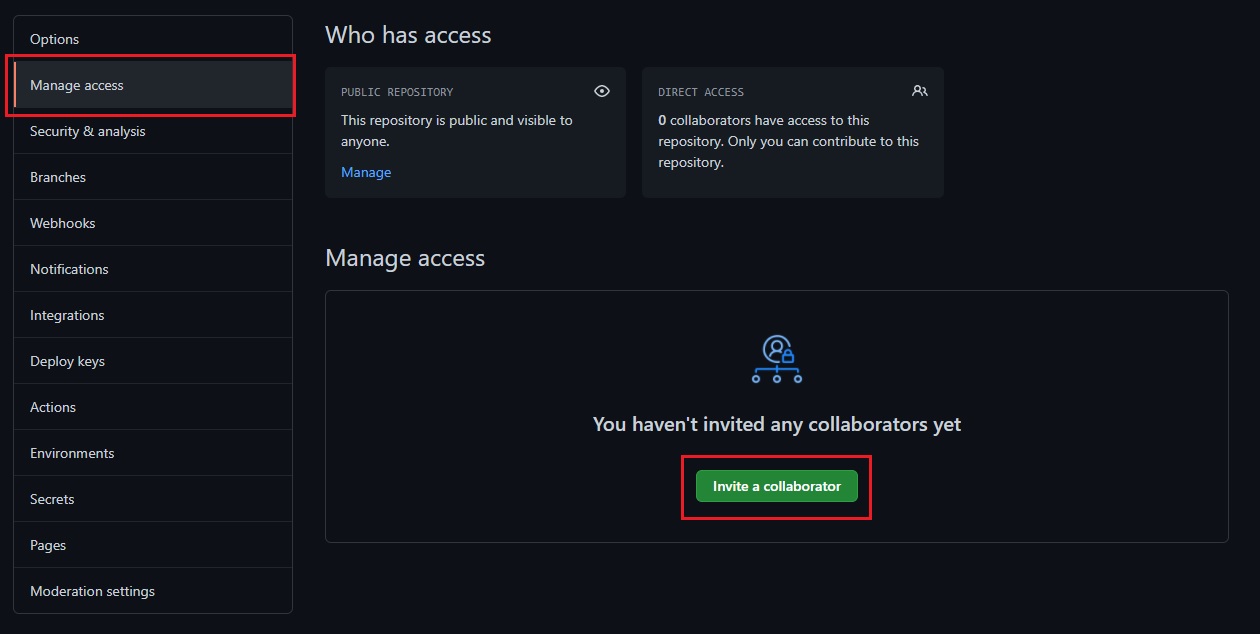
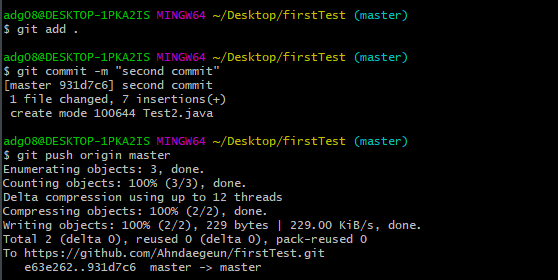
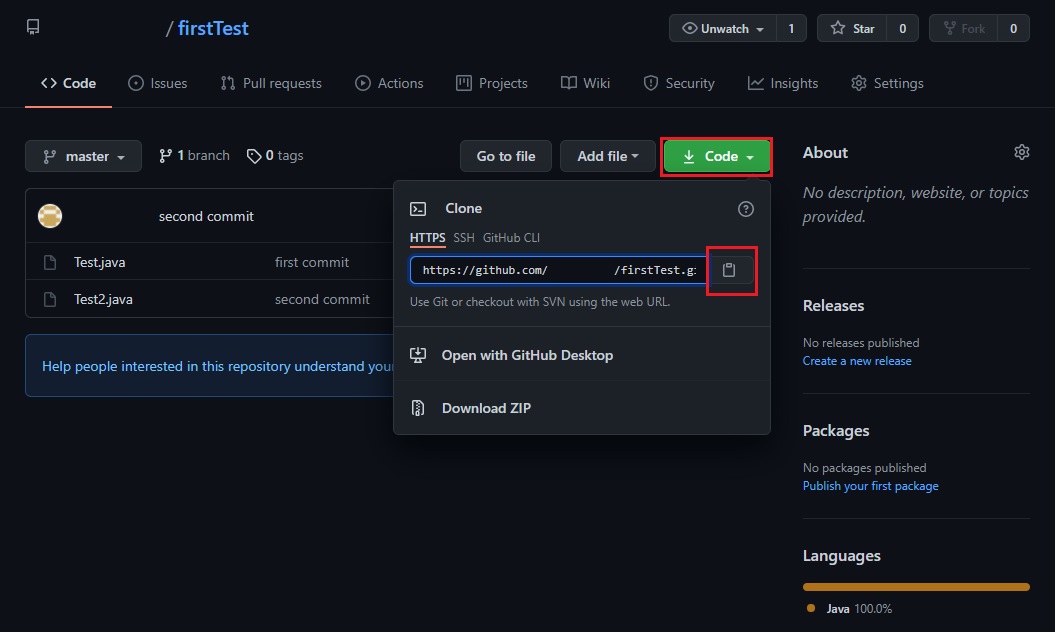
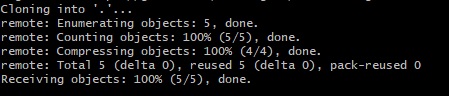
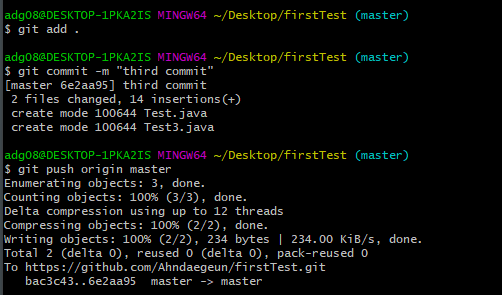
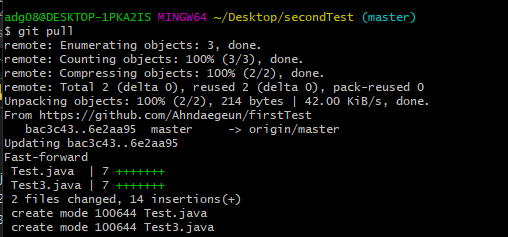
public class Student {
public int modifyStudent() {
return 0;
}
}
생성자와 비슷하게 생겼지만 리턴 타입이 있고 클래스 이름과 동일한 것이 아닌 작동에 대해 작명을 해줘야 한다
메서드란 어떠한 동작을 한다고 생각을 해보면 좋을듯 하다.
메서드는 재료를 받아서 내부적으로 어떠한 동작을 하고 결과물을 반환해준다
위의 그림처럼 쌀, 밥솥, 물이라는 재료를 밥 짓기라는 메서드에 넣어주면 쌀밥이 나온다. 여기서 쌀, 밥솥, 물은 매개변수이고, 밥 짓기는 매소드 내부에서 쌀, 밥솥, 물이라는 매개변수를 사용해서 쌀밥이라는 결과물을 내기 위한 동작을 실행하는 부분이며, 쌀밥은 리턴 값이 된며 리턴 타입은 밥이 되는 것이다.
리턴 값과 리턴타입의 관계를 보면 쌀밥은 밥이라는 큰 카테고리 안에 들어갈 수 있다. 매개변수로 쌀이 아니라 보리를 넣는다면 보리밥이 나오지만 밥이라는 큰 카테고리는 같다.
매개변수와 리턴값
경우의 수는 4가지가 있다
매개변수가 있고 리턴 값이 없는 경우
매개변수가 있고 리턴 값이 있는 경우
매개변수가 없고 리턴 값이 없는 경우
매개변수가 없고 리턴 값이 없는 경우
이렇게 4가지의 경우가 있다
리턴 값에는 여러 가지가 올 수 있다. 너무 다양하고 많지만 몇 가지 예시를 들자면
void : 리턴 값이 없는 경우 사용된다
int, double, char, byte, boolean 등 기본 타입 : 기본 타입의 값을 리턴해줄 수 있다
String, List, 객체 등 참조 타입 : 객체, 클래스 등 모든 참조 타입으로도 반환이 가능하다
매개변수를 받아와야 하는데 메서드를 작성하는 시점에 몇 개의 매개변수를 받아와야 할지 모르는 경우 혹은 계속 개수의 변경이 있어야 한다면 배열로 받아올 수도 있다
메서드 오버 로딩
오버 로딩 방법은 생성자와 같으며 리턴 타입의 변경은 의미가 없다
메서드의 호출
해당 클래스를 통해 인스턴스를 생성해주고 생성된 인스턴스를 통해서 메서드를 호출해준다
public class StudentTest {
public static void main(String[] args) {
Student s1 = new Student("홍길동", 90, 89);
int s1Score = s1.getTotalScore();
}
}
class Student {
public String name;
public int korScore;
public int engScore;
public Student(String name, int korScore, int engScore) {
this.name = name;
this.korScore = korScore;
this.engScore = engScore;
}
public int getTotalScore() {
return korScore + engScore;
}
}
생성자가 하나라도 있으면 Default생성자는 컴파일 단계에서 자동으로 생성되지 않으며 Default생성자가 필요하다면 생성자 오버 로딩을 통해 Default생성자를 생성해줘야 사용이 가능하다
public class Student {
public Student() {
}
}
객체 생성 시 사용하는 new연산자에서 소괄호 안에 넣어줄 매개 변수를 생성자에서 설정해 줄 수 있다
생성자를 작성하지 않으면 컴파일 시에 default생성자가 만들어지며 위의 코드와 똑같이 만들어진다
메서드와 동일하게 생겼지만 반환 값이 없고 클래스 이름과 동일한 것이 특징이다
생성자를 여러 개 생성할수 있다
생성자를 여러개 만들어주는 것을 생성자 오버 로딩이라고 하며 매개변수의 타입, 개수 또는 타입과 개수가 모두 다른경우 오버로딩이 가능하다
불가능한 경우
public class Student {
public int num;
public String name;
public int age;
public int regNo;
public Student (int num, int age) {
this.num = num;
this.age = age;
}
public Student (int num, int regNo) {
this.num = num;
this.regNo = regNo;
}
}
위와 같이 매개변수에 들어가는 값의 개수가 같을 때 같은 타입이면 오류가 생긴다
오버 로딩 시에는 매개변수의 변수명은 중요하지 않으며 타입과 개수가 다른 것이 중요하다
가능한 경우
public class Student {
public int num;
public String name;
public int age;
public int regNo;
public Student (int num, int age) {
this.num = num;
this.age = age;
}
public Student (int num, String name) {
this.num = num;
this.name = name;
}
}
위의 경우에는 매개변수의 개수는 같지만 타입이 다르기 때문에 오버 로딩이 가능하다
this
위의 코드를 보면 모두 생성자 안에서 this라는 키워드를 사용해줬는데 자기 자신을 뜻한다
생성자를 보면 매개변수로 받아오는 변수의 이름이 필드의 변수 이름이랑 같다. 일반적으로 위와 같이 작성을 해주는데 그때 필드가 가지고 있는 변수와 매개변수로 받아오는 변수를 구분해주기 위해 this라는 키워드를 사용할 수 있다.
this는 생성된 인스턴스 자신을 가리키는 키워드로 Student클래스로 A와 B라는 인스턴스를 생성했을 때 A의 this는 A가 가지고 있는 필드와 메서드, 생성자를 가리키고, B의 this는 B가 가지고있는 필드와 메서드, 생성자를 가리킨다.
Field, Method, Constructor 모두 위치가 정해져 있는 건 아니지만 상단에 Field, 중간에 Constructor, 하단에 Mehtod를 작성해주는 것이 일반적이다
Field에서 선언해주는 변수를 맴버변수라고 부르며 외부에서도 값을 가져오거나 변경이 가능하다
public class Test {
//Field
String str;
int num;
boolean flag;
}
변수의 타입은 기본타입부터 레퍼런스 타입까지 모두 선언과 사용이 가능하다
public class TestExample {
public static void main(String[] args) {
Test test = new Test();
System.out.println(test.str);
test.str = "Hello";
}
}
위의 코드와 같이 main이 들어간 TestExample클래스에서 Test 클래스를 불러와서 출력하거나 변경하는 것이 가능하다.
Field에서 선언한 변수들의 초기값은 앞선 포스팅에 나와있듯이 기본타입은 0, 0.0, false 등이고 참조 타입의 기본값은 모두 null값으로 초기화된다.
변수의 사용은 인스턴스 변수, 즉 test뒤에. 을 붙여 사용해주면 된다.
Test Class를 사용해 여러 개의 인스턴스(객체)를 생성했을 때 각 인스턴스 별로 갖고 있는 메모리의 주소 값이 다르므로 동일한 내용이 들어있다 해도 각 인스턴스 안에 변수는 다른 값을 가지고 있다.
public class TestExample {
public static void main(String[] args) {
Test test1 = new Test();
Test test2 = new Test();
test1.str = "Hello";
System.out.println(test2.str);
}
}
위와 같이 코드를 작성했을 때 test2.str의 값은 null이 나오게 된다.
test 1.str의 주소와 test2.str의 주소가 다르기 때문에 이런 결과가 나오게 되는데 만약 test 1과 test2의 주소가 같은 주소를 참조한다면 test2.str 또한 Hello가 되었을 것이다.
이를 통해 인스턴스 생성 시 각각의 인스턴스는 다른 주소 값에 새로 생성된다는 걸 알 수 있다.
TRUNC : 주어진 수 n1의 소숫점 이하 n2 + 1번째 자리부터 절삭(반올림되지 않음)
n2가 음수이면 정수 부분의 n2자리에서 반올림(ROUND)또는 절삭(TRUNC) / 0으로 반환
-1, -10, -100 순으로 1, 10, 100의 자리가 됨
SELECT ROUND(123.456, 1) FROM DUAL;
//출력 : 123.5
SELECT ROUND(567.899, -2) FROM DUAL;
//출력 : 600
SELECT TRUNC(123.456, 1) FROM DUAL;
//출력 : 123.4
SELECT TRUNC(567.899, -2) FROM DUAL;
//출력 : 500
n2가 음수, 양수에 관계없이 ROUND는 올림, TRUNC는 버림이 된다.
MOD(n1, n2)
n1을 n2로 나눈 나머지를 반환한다
SELECT MOD(10, 3) FROM DUAL;
//출력 : 1
REMAINDER(n1, n2)
n1을 n2로 나눈 나머지를 반환한다
SELECT REMAINDER(10, 3) FROM DUAL;
//출력 : 1
MOD와 REMAINDER 모두 나머지를 반환하지만 내부적으로 동작하는 방식이 다르다
일반적으로는 MOD를 많이 사용한다
WIDTH_BUCKET(n1, min, max, block_cnt)
하한 값 min과 상한 값 max로 정한 구간을 block_cnt개수의 블록으로 나누었을 때 n1이 속한 구간 순번을 반환
min, max값은 반대로 대입도 가능하다
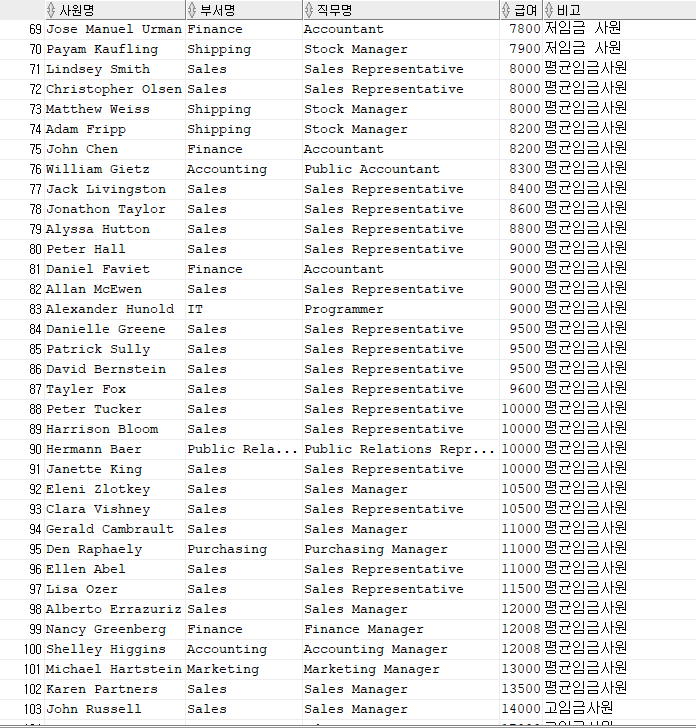
아래의 코드는 참고를 위해 조인과 케이스 등을 사용하였지만 대략적인 사용방법만 알고 넘어가도록 하자
SELECT A.EMP_NAME AS 사원명,
C.DEPARTMENT_NAME AS 부서명,
B.JOB_TITLE AS 직무명,
A.SALARY AS 급여,
CASE WHEN WIDTH_BUCKET(A.SALARY, 2000, 20000, 3)=1 THEN
'저임금 사원'
WHEN WIDTH_BUCKET(A.SALARY, 2000, 20000, 3)=2 THEN
'평균임금사원'
ELSE
'고임금사원'
END AS 비고
FROM HR.EMPLOYEES A, HR.JOBS B, HR.DEPARTMENTS C
WHERE A.DEPARTMENT_ID=C.DEPARTMENT_ID
AND A.JOB_ID=B.JOB_ID
ORDER BY 4;
위와 같이 출력이 되며 급여를 기준으로 3구간으로 나눠서 저임금, 평균임금, 고임금 사원으로 나눈 결과이다.